



C'est grand comment la donnée?
Tout savoir sur les unités de mesure de la donnée et leur valeur actuelle

329 Exabytes de données récoltées dans le monde par jour, ça vous fait une belle jambe, non? A l’approche de ce tunnel, sûrement que cette information ne vous parle pas vraiment, et pourtant on est très nombreux à s’en extasier (à commencer par moi dans “La porte d’entrée” par exemple).
C’est pourtant essentiel d’avoir un peu de maîtrise sur les différentes unités de mesure qui permettent de quantifier les données pour comprendre l’ampleur du phénomène de “Big Data”.
Imaginez que vous n’ayez aucune idée de ce que représente un mètre par exemple. Pour vous, Victor Wembanyama et Mimie Mathy auraient à peu près la même taille. Ça vous semble ridicule, non? Eh bien, si vous n’avez aucune idée de ce que représentent les Ko, Gb ou To pour n’en citer que quelques-uns, c’est le genre d’erreurs que vous ferez dès qu’il s’agira de parler de données.

🎯L’objectif de ce tunnel est donc de vous aider à comprendre comment on mesure la donnée et à vous faire une idée des ordres de grandeur actuels. Après ça, normalement un byte devrait être aussi intuitif pour vous qu’un mètre, une seconde ou un litre.
Au menu du jour :
🧮 Bits, Bytes, octets : on démystifie tout ça
🔍 Kilo, giga, tera, exa, etc.: que veulent dire ces préfixes?
📊 Un tableau comparatif pour avoir quelques ordres de grandeur
📈 La loi de Moore en détail
☁️ Et le cloud dans tout ça?
🌊 Les challenges que représente un monde noyé dans la data
Comprendre les unités de mesure
🚨 Accrochez vos ceintures, cette partie du tunnel est assez technique 🚨
Au commencement, il y a le bit
Humanisons un peu la data. Si je vous demande de me mesurer, que feriez-vous? Mesurer la longueur de mon corps? Mesurer la circonférence de mon corps? Mesurer mon poids, ma puissance, ma vitesse? Bref, il y aurait une infinité de choix et d’unités possibles selon l’objectif de votre mesure.
Pour la donnée, c’est pareil, il existe une très grande variété d’unités de mesure qui permettent toutes de capter un aspect de la donnée. Certaines d’entre elles sont absolument essentielles à connaitre :
🧬 Le bit : “Bit”, c’est la contraction de Binary Digit, ou chiffre binaire, c’est un chiffre qui est soit égal à 1, soit égal à 0.
C’est l’unité fondamentale, car, toute la donnée qui existe de façon numérique n’est comprise par les ordinateurs qu’avec des 0 et des 1, c’est à dire avec des bits.
Mais pourquoi un ordinateur ne comprend-il que les 0 et les 1? En fait, un ordinateur, c’est tout simplement l’assemblage de millions de circuits électriques qui interagissent ensemble. Chacun de ces circuits électriques peut se trouver dans 2 états : chargé électriquement (1) ou non-chargé électriquement (0). C’est donc avec des suites de 0 et de 1 (de bits) que l’ordinateur peut définir des données1.
📦 Le byte et l’octet : Un octet, c’est une suite de 8 bits. Par exemple 01100111 est un octet. Le byte, c’est l’unité qui permet de mesurer la capacité de stockage d’un ordinateur. Dans un byte, on va pouvoir déposer une information, une donnée élémentaire qui pourra être utilisée par un programme informatique : une lettre, un chiffre, un signe, un morceau de pixel…
Pourquoi l’octet et le byte sont dans la même bullet point, vous demandez-vous peut-être ? Tout simplement parce que dans un byte, on peut stocker un octet. Dans le langage courant on confond souvent byte et octet car les deux unités représentent la même valeur, même si le byte représente la capacité de stockage et l’octet est le nombre de bits (8) qui tiennent dans un byte.
Sachez que le nombre de bits dans un byte (8) n’a pas été choisi au hasard, si vous voulez savoir pourquoi 8, j’ai trouvé une belle explication ici.
⏱️ Le débit binaire (bit/s) : Il s’agit de la mesure de la quantité de données numériques (bits) transmises par unité de temps (secondes). C’est cette unité que vous pouvez voir sur votre box (vous avez un débit de “Download” qui correspond au nombre de bits que vous pouvez télécharger par secondes et un débit de “Upload” qui correspond au nombre de bits que vous pouvez envoyer par secondes.
Pour chaque unité, la même façon de compter
Un bit, c’est donc ce qui permet de mesurer la donnée et c’est seulement un chiffre égal à 0 ou 1? Avec ça, on va avoir besoin d’un bon paquet de bits pour mesurer toute la donnée du monde…
Heureusement, de même qu’on a inventé le kilomètre pour éviter de compter en milliers de mètres ou l’année lumière pour éviter de compter en dizaines de milliards de kilomètres, on a inventé des préfixes, communs à toutes les unités de mesure pour garder des nombres lisibles lorsque les ordres de grandeur grandissent.
Voici un tableau récapitulatif de ces préfixes, que vous retrouverez partout (pas spécifiquement aux ordinateurs d’ailleurs, on pourrait par exemple parler d’ “Exa-litre” si on avait très très soif…)
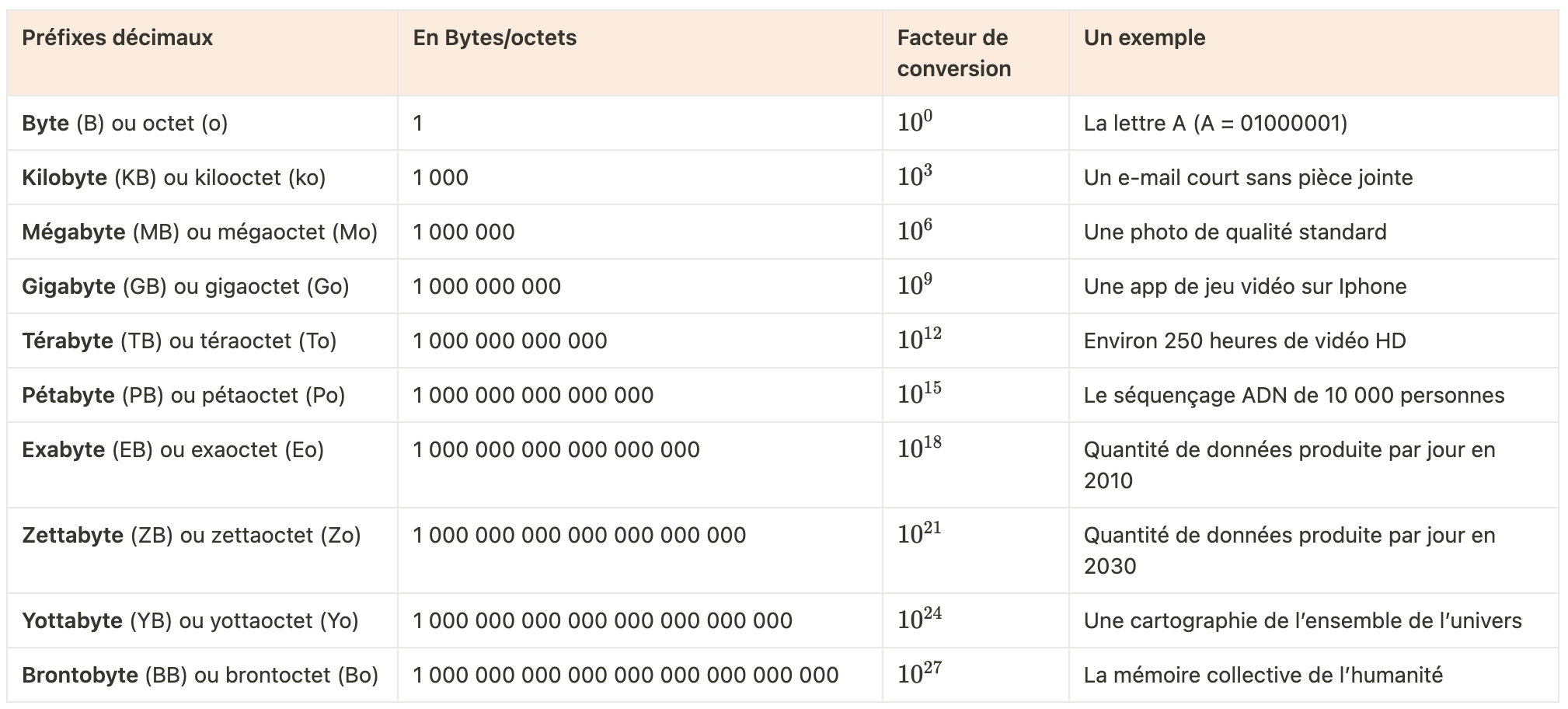
🤓 Bravo, vous avez fait le plus dur! Maintenant qu’on sait comment on mesure la donnée, essayons de comprendre à quel point on peut parler de “Big Data”.
Comment est-on passé du byte à l’Exabyte?
Étape 1: La loi de Moore ou l’augmentation de nos capacités de stockage
Il ne vous a pas échappé sur le tableau précédent qu’entre 2010 et 2030, on multiplie par 1000 la quantité de données journalières produite, comment est-ce possible?
L’essor de la quantité de données disponibles, qui fait que l’on parle aujourd’hui du phénomène du “Big Data” a été permis car on arrive à stocker des bits de donnée de plus en plus facilement.
Par exemple, en 1980, il fallait une salle entière remplie de gros ordinateurs et de supports de stockage pour contenir 250 Go de données, ce qui tient aujourd'hui dans un iPhone.
Rappelez-vous, si un bit correspond à un circuit électrique chargé ou non (0 ou 1), des milliards de bits, ça prend de la place. Si on n’avait pas réussi à réduire à ce point l’espace physique qu’il fallait pour stocker nos bits, on n’aurait jamais eu besoin d’inventer les “Bronto”, “Yotta”, “Zetta” & cie, car on n’aurait jamais eu la place d’avoir autant de circuits électriques sur terre.
En fait notre capacité à stocker toujours plus de données dans toujours moins d’espace a été théorisée en 1965 par le cofondateur d'Intel, Gordon Moore dans sa loi éponyme2.
Il faisait la prédiction que la densité des transistors, c’est-à-dire le nombre de transistors que l’on peut placer sur un circuit électrique (qui correspond à la capacité de stockage), double tous les deux ans. En d’autres termes : La capacité de stockage croit de façon exponentielle!

La loi de Moore était une prédiction sans véritable preuve scientifique et elle s’est avérée empiriquement extrêmement juste, ce qui a surpris jusqu’à Moore lui-même qui ne pensait pas que ces prédictions seraient aussi justes pendant aussi longtemps.
Étape 2 : Le cloud ou la distribution massive de ces capacités de stockage
Je le répète encore une fois : stocker un bit de données, ça prend de la place physiquement. Alors, quand on dit que la capacité de stockage augmente de façon exponentielle, la question qu’on peut se poser est: où ça? Réponse : Dans le cloud, évidemment!
Le cloud, c’est le nom que l’on donne à la manière dont on se partage les capacités mondiales de stockage de données depuis les années 2000. Certes, avec la loi de Moore, on a pu voir que les capacités de stockage de data augmentaient de façon exponentielle tous les deux ans, mais ce n’est ni vous ni moi qui détenons ces fameux circuits électriques et microprocesseurs.
Les serveurs (c’est-à-dire les machines composées de milliards de circuits électriques qui permettent de stocker des bits de donnée), ils sont détenus en grande partie par ceux qu’on appelle les “géants du numérique” (Google, Amazon ou Apple aux Etats-Unis, Alibaba ou Baidu en Chine entre autres).
Ces entreprises ont de véritable “Data centers”, qui sont des bâtiments remplis de grandes tours d’ordinateurs sans écrans (les fameux serveurs) reliées par des millions de fils électriques. Leur business model consiste à louer un pourcentage infime de ces grandes tours à vous et moi pour qu’on y stocke notre donnée.
Ainsi, quand vous prenez une photo sur votre Iphone et qu’elle est synchronisée par iCloud (le service Cloud d’Apple), votre photo est convertie en bits qui vont être stockés dans un de ces gigantesques data centers.
Grâce au cloud, on n’a pas besoin de posséder les infrastructures physiques pour stocker nos données, ce qui a largement contribué à l’essor du “Big Data” puisque désormais on stocke tout et n’importe quoi, au point, parfois, de ne plus se rappeler qu’en stockant, on utilise l’électricité de ces data centers…

Risque-t-on d’avoir trop de données?
On peut se demander à quoi ça sert d’avoir autant de données? Certes, toujours plus de données stockées veut dire toujours plus de savoir et est synonyme d’avancée technologique… qu’il s’agisse pour les entreprises d’obtenir des informations sur leurs utilisateurs, pour les scientifiques de modéliser des phénomènes nouveaux ou encore pour les algorithmes de devenir plus intelligents (il n’y a qu’à voir la quantité astronomique de données sur lesquelles ChatGPT a été entrainé3).
Néanmoins, il ne faut pas se tromper, accumuler de plus en plus de données comprend aussi de nombreux risques :
🌍 D’abord le risque écologique. On l’a dit, l’unité fondamentale est le bit, qui correspond à un circuit électrique chargé ou non. Quand on en est à parler de Brontobytes, ça en fait de l’électricité, non?
Selon un rapport de WWF4, le secteur numérique représentait 2% des émissions mondiales de gaz à effet de serre en 2018, soit autant que le trafic aérien mondial. 2% en 2018… mais combien demain puisque les projections de la quantité de données disponibles ne font qu’exploser ?
Petit tip : à la sortie de ce tunnel, pensez à supprimer vos archives de mails par exemple, ça éteindra des circuits électriques dans le cloud 😉

🤯 Ensuite, le risque de se noyer dans trop de données. Quand on a trop de données à disposition, il y a un véritable travail intellectuel à effectuer pour trouver les données qui ont de la valeur, et, à vouloir toujours utiliser plus de données, on finit par rater l’essentiel.
Petit tip : N’ayez jamais peur d’ignorer des données pour comprendre un phénomène : toute la donnée disponible n’est pas forcément utile.
🛡️Enfin, les risques de piratages. Nous sommes tous une composante du phénomène de Big Data car nous produisons de plus en plus de données que nous stockons dans le cloud, ce qui nous rend plus vulnérables aux piratages en tout genre (vol de données bancaires, usurpations d’identité, etc.)
Petit tip : Arrêtez d’avoir un seul mot de passe que vous partagez pour tous vos comptes. Quand vous créez un mot de passe, vous le stockez dans un serveur qui ne vous appartient pas et qui risque d’être piraté un jour. Si c’est le cas (et vous ne pouvez rien y faire), il vaut mieux éviter de donner aux pirates l’accès à l’intégralité de vos données numériques, non?
Sur ces quelques petits conseils, je vous invite maintenant à sortir de ce 4ème tunnel 🎉.
Je voudrais prendre le temps de vous remercier de me lire chaque semaine et de me faire les retours incroyables que vous me faites ❤️. Je vous en prie, continuez!
Comme d’habitude, pour ceux qui ne sont pas encore abonné, n’hésitez pas à le faire, et pour tout le monde si cet article peut servir dans votre entourage, n’hésitez pas à le partager. Merci infiniment!
P.S: Pour info, ce mail pèse 131ko 😉
Pour une explication encore plus détaillée à propos de l’usage de 0 et de 1 pour communiquer avec des machines, je vous recommande l’excellent reportage Coder, pourquoi? de la série Netflix En Bref
Technique, mais engageant et didactique !!! Bravo